I placed in the top 10% of my first Kaggle competition. If you are not familiar with it,
Kaggle is an ongoing forum for competitive data science. Individuals and teams compete to
create the best model for data sets provided by industry and sometimes academia.
Individuals who enter are ranked as either Novice, Kaggler and Kaggle Master. To become
a Kaggle master, one must place in the top 10% of two competitions; and in one of the top
10 slots of a third competition.
I’ve talked about Kaggle in many of my presentations. I’ve also used Kaggle data in
my books. Until now, I had yet to actually enter a Kaggle competition. I decided it was
finally time to try this for myself. I competed in the Otto Group Product Classification
Challenge that ended on May 18th, 2015. My score was sufficient to land in the top 10%,
so I’ve completed one of the requirements for Kaggle master. My Kaggle profile can be
seen here.
My goals for entering were:
- See how hard Kaggle actually is, and move towards a Kaggle master designation.
- Learn from the other Kagglers and forums.
- Build a basic toolkit that I will use for future Kaggle competitions.
- Gain an example (from my entry) for the Artificial Intelligence for Humans series.
- Maybe get an idea or two for my future dissertation (I am a phd student at Nova Southeastern University).
The Otto Classification Challenge
First, I will give a brief introduction to the exact nature of the Otto Classification
Challenge. For a complete description, refer to the Kaggle description(found here).
This challenge was introduced by the Otto Group, who is the world’s largest mail order
company and currently one of the biggest e-commerce companies, mainly based in Germany
and France but operating in more than 20 countries. They have many products sold over
numerous countries. They would like to be able to classify these products into 9
categories, using 93 features (columns). These 93 columns represent counts, and are
often zero.
The data are completely redacted. You do not know what the 9 categories are, nor do you
know the meaning behind the 93 features. You only know that the features are integer
counts. Most Kaggle competitions provide you with a test and training dataset. For the
training dataset you are given the outcomes, or correct answers. For the test set, you
are only given the 93 features, and you must provide the outcome. The test and training
sets are divided as follows:
- Test Data: 144K rows
- Training Data: 61K rows
You do not actually submit your model to Kaggle. Rather, you submit your predictions
based on the test data. This allows you to use any platform to make these predictions.
The actual format of a submission for this competition is the probability of each of
the 9 categories being the outcome. This is not like a university multiple choice test
where you must submit your answer as A, B, C, or D. Rather, you would submit your
answer as:
- A: 80% probability
- B: 16% probability
- C: 2% probability
- D: 2% probability
I wish college exams were graded like this! Often I am very confident about two of the
answers, and can eliminate the other two. Simply assign a probability to each, and you
get a partial score. If A were the correct answer for the above, I would get 80% of the
points.
The actual Kaggle score is slightly more complex than that. Rather, you are graded on a
logarithm based scale and are very heavily penalized for having a lower probability on
the correct answer. The following are a few lines from my submission:
1 | 1,0.0003,0.2132,0.2340,0.5468,6.2998e-05,0.0001,0.0050,0.0001,4.3826e-05 |
Each line starts with a number that specifies the data item that is being answered.
The sample above shows the answers for items 1-5. The next 9 values are the probabilities
for each of the product classes. These probabilities must add up to 1.0 (100%).
What I Learned from Kaggle
If you want to do well in Kaggle, the following are very important topics, along with
the tools I used.
- Deep Learning - Using H2O and Lasagne
- Gradient Boosting Machines (GBM) - Using XGBOOST
- Ensemble Learning - Using NumPy
- Feature Engineering - Using NumPy and Scikit-Learn
The two areas that I learned the most about, during this challenge, were GBM parameter
tuning and ensemble learning. I got pretty good at tuning a GBM. The individual scores
for my GBM’s were in line with those used by the top teams.
Before Kaggle I typically used only one model, if I were using neural networks, I just
used neural networks. If I were using an SVM, Random Forest or Gradient Boosting, I stuck
to just that model. With Kaggle, it is critical to use multiple models, ensembled to
produce better results than each of the models could produce independently.
Some of my main takeaways from the competition:
- GPU is really important for deep learning. It is best to use a deep learning package that supports it, such as H2O, Theano or Lasagne.
- The t-sne visualization is awesome for high-dimension visualization and creating features.
- I need to learn to ensemble better!
This competition was the first time I used T-SNE. It works like PCA in that it is capable
of reducing dimensions, however, the data points separate in such a way that the
visualization is often clearer than PCA. This is done using a stochastic nearest
neighbor process. I plan to learn more about how t-sne actually performs the reduction,
compared to PCA.

My Approach to the Otto Challenge
So far I’ve only worked with single model systems. I’ve used models that contain ensembles
that are “built in”, such as random forests and gradient boosting machines. However, it
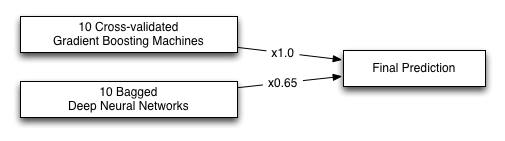
is possible to create higher-level ensembles of these models. I used a total of 20 models,
this included 10 deep neural networks and 10 gradient boosting machines. My deep neural
network system provided one prediction and my gradient boosting machines provided the other.
These two predictions were blended together, using a simple ratio. The resulting prediction
vector was then normalized so that the sum equaled 1.0(100%).
I did not remove or engineer any fields. For both model types I converted all 93
attributes into Z-Scores. For the neural network I normalized all values to be in a
specific range.
My 10 deep learning neural networks used a simple bagging method. I averaged the
predictions from 20 different neural networks. Each of these neural networks was created
by choosing a different 80/20 split between training and validation. The neural network
was trained on the training data until the validation score did not improve for 25 epochs.
Once training stopped I used the weights from the epoch that produced the highest training
score. This process is a simple form of bagging called bootstrap aggregation.
My 10 gradient boosting machines (GBM) were each components of a 10-fold cross-validation.
I essentially broke the Kaggle training data into 10 folds and used each of these folds
as a validation set, and the others as training. This produced 10 gradient boosting machines.
I then used an NxM coefficient matrix to blend each of these together. Where N is the
number of models, M is the number of features. In this case it was a 10x9 grid. This
matrix weighted each of the 10 model’s predictive power in each of the 9 categories.
These coefficients were a straight probability calculation from the confusion matrix of
each of the 10 models. This allowed each model to potentially specialize in each of the
9 categories.
I spent considerable time tuning my GBM. I used Nelder-Mead searches to optimize my
hyper-parameter vector. I ultimately settled on the following parameters:
1 | params = {'max_depth': 13,'min_child_weight': 4,'subsample': .78,'gamma': 0,'colsample_bytree': 0.5, 'eta':.005, 'threads':24} |
What Worked Well for Top Teams
The top Kaggle teams made use of more sophisticated ensemble techniques than I did.
This will be my primary learning area for the next competition. You can read about
some of the top models here:
- The Top Scoring Model
- Relatively Simple Model for a Top 25 Score
- Share Your Models
- One of the Top Ten
- TSNE & Meta-Bagging
The above write-ups are very useful, I’ve already started examining their approaches.
Some of the top technologies discussed were:
- Feature Engineering
- Input Transformation - good write up here
- log transforms
- sqrt(x + 3/8) - Not sure what this one is called, but I saw it used a few times
- z-score transforms
- ranged transformation
- Hyperparameter Optimization
- Nelder-Mead
- Spearmint
I will probably not enter another Kaggle until the fall of this year. This blog post
will be updated to contain my notes as I investigate other techniques for this
competition.